Overview
Things to know before you configure
Collins configuration files are type safe. That is, you can't create a configuration that will lead to a runtime error. If collins detects a configuration error it will fail to start. If you modify a config after the system starts and that config is invalid, it will not load and collins will complain loudly. If this is not the case, please file a bug.
Every type of configuration comes with a reference config. Reference configuration files can be found in
the github repo.
Reference files are not modified by users, they serve to provide Collins with default values as well as to
tell it what the appropriate value types are (lists, strings, etc). Most reference configurations come with
some level of documentation as well. In general you should use and make modifications to conf/application.conf.
The configuration file that you create for collins is overriding the values found in the reference configs. There is a sample configuration in the github repo for you to use as a starting point.
You can pass your configuration file to collins by using a system property. Pass -Dconfig.file=/path/to/file
will cause that file to be used for the application.
General
Configuration options that don't fit anywhere else
Application Specific
These configuration aspects are specific to the play framework.
| Key | Type | Description |
|---|---|---|
| application.secret | String | A secret key used to secure your cookies. If you deploy several collins instances be sure to use the same key. |
| parsers.text.maxLength | Integer | The maximum allowable size of a body. Be sure to make this large enough to allow for LSHW/LLDP uploads. |
| evolutionplugin | String | Set to disabled in production, or enabled in development |
application.secret="AbFgHx0eJx8lalkja812389uasdlkajsdlka98012398uasdlkasdklajsd81298" parsers.text.maxLength=1048576 evolutionplugin = disabled
Crypto
The only crypto configuration available is the key. The crypto key must not be changed after the system is initialized for the first time or you will be unable to decrypt data.
| Key | Type | Description |
|---|---|---|
| crypto.key | String | A 63 character random string. Be sure that any Collins instances using the same database have the same crypto.key |
crypto.key = "lkkajsdlkajsdlkajsdlkajsdlkajsdlkajsdlkajsdlkajsdlkajsdlkajsdla"
Database
db {
collins {
logStatements = false
user = "sa"
password = ""
driver = "org.h2.Driver"
url = "jdbc:h2:mem:play;IGNOERCASE=true"
}
}
db {
collins {
logStatements = false
user = "root"
password = ""
driver = "com.mysql.jdbc.Driver"
url = "jdbc:mysql://localhost/collins?autoReconnect=true&interactiveClient=true"
}
}
LSHW Parsing
Due to how LSHW handles PCIe flash devices, you have to give the parser a hint as to which attribute values indicate that the device is in fact a flash storage device. Here you can specify the string to match on and the size to use if the match is found.
| Key | Type | Description |
|---|---|---|
| lshw.defaultNicCapacity | Long | When parsing NIC capicity collins tries a few things. It first uses the capacity value, if it is found. If not, it uses the size value, if it is found. If neither capacity or size are found, it then looks in the product name for the string '10-gig'. If it finds that string, it assumes the size is 10000000000 bits. If none of these succeed, it will use the lshw.defaultNicCapacity value. This configuration is specified in bits, and there is no default value. If this value is not set, and collins tries to use it, it will throw an exception and fail to parse the LSHW data. |
| lshw.flashProduct | String | Deprecated Product string to look for in LSHW output to detect a flash device. Defaults to flashmax. This is deprecated, and will be removed in a future version. Please use lshw.flashProducts instead. |
| lshw.flashProducts | Set[String] | Product strings to look for in LSHW output to detect a flash device. Defaults to ["flashmax"], and includes lshw.flashProduct. |
| lshw.flashSize | Long | If the flashProduct matched, the size to use. Defaults to 1400000000000. |
| lshw.includeDisabledCpu | Bool | Whether CPUs marked as disabled should be included. Defaults to false. |
| lshw.includeEmptySocket | Bool | Whether sockets with no CPU should be included. Defaults to false. |
lshw {
defaultNicCapacity = 10000000000
flashProducts = ["flashmax","fusionIO","TachION Drive"]
flashSize = 1400000000000
}
Query Log
The query log is primary used for development but allows you to turn on database query logging and API (find/search) logging.
| Key | Type | Description |
|---|---|---|
| querylog.enabled | Boolean | Whether to log database queries |
| querylog.includeResults | Boolean | Defaults to false. If the query log is enabled, and includeResults is true, query results will also be logged |
| querylog.prefix | String | Defaults to "QUERY: ". A prefix to use in the log message. |
| querylog.frontendLogging | Boolean | Defaults to false. If true, API queries are logged |
querylog {
enabled = false
includeResults = false
prefix = "QUERY: "
frontendLogging = false
}
Authentication
Setting up user authentication and authorization
Authentication Namespace authentication
Collins supports a variety of authentication backends along with a flexible API endpoint based permissions system. Some features also have specific permissions.
Collins comes bundled with a small in-memory authentication mechanism for testing, file based authentication for small or simple installations, and LDAP based authentication for large or enterprise installations. If using LDAP we recommend running an LDAP slave on the collins node itself in order to be resilient to large outages where the usual LDAP infrastructure might be unavailable.
| Key | Type | Description |
|---|---|---|
| type | String | Defaults to default, which is the in-memory database. Other valid values are file or ldap |
| permissionsFile | String | Path to the YAML file containing the application permissions. There is a sample permissions file below. Every API endpoint has a name associated with it. You can configure per endpoint permissions as well as some feature permissions. |
| permissionsCacheSpecification | String | The guava cache specification to use for the permissions file, as described in com.google.common.cache.CacheBuilderSpec. Defaults to "expireAfterWrite=30s". |
| adminGroup | Set[String] | A list of groups for administrative users. Users that have one of these groups will be in the admin group. Note that being in the adminGroup doesn't always mean you will have access to something, but by default it will. Using the permissionsFile it is possible to configure permissions such that even someone in the admin group can't access a partilar feature or API endpoint. |
The permissions example below creates two user groups, admins and tools. User groups are just named groups of users that are stored in the YAML file. This is useful for people authenticating with flat files or if you want to store some group information here. The admins user group has two users, alan and bmatheny. The tools user group has three users. There are two feature permissions specified, one for rate limiting and the other for who can see encrypted tags, like passwords. The last permission is for the powerStatus API endpoint and is open to a broader group of users. Every API permission name is documented in the API documentation.
users:
admins:
- "alan"
- "bmatheny"
tools:
- "jetpants"
- "itouch"
- "phil"
permissions:
feature.noRateLimit:
- "u=tools"
feature.canSeeEncryptedTags:
- "u=admins"
- "u=tools"
- "g=infra"
controllers.AssetManagementApi.powerStatus:
- "g=infra"
- "g=ops"
- "u=admins"
- "u=tools"
authentication {
type = default
permissionsFile = "conf/permissions.yaml"
permissionsCacheSpecification = "expireAfterWrite=30s"
adminGroup = [Infra]
}
LDAP Authentication Namespace authentication.ldap
At Tumblr LDAP is the primary authentication mechanism. We have tested that this code works with at least RFC 2307, IPA, and the OS X admin server.
| Key | Type | Description |
|---|---|---|
| host | String | The LDAP host to authenticate against. This is a required configuration. |
| ssl | Boolean | Whether or not to use LDAPS when communicating with the LDAP server. Defaults to false |
| schema | Enum | One of rfc2307 or rfc2307bis. This is a required configuration. |
| searchbase | String | The LDAP search base to use. This is a required configuration. |
| usersub | String | Where to find users in the LDAP schema. This is a required configuration. |
| groupsub | String | Where to find groups in the LDAP schema. This is a required configuration. |
| anonymous | Boolean | Whether to use anonymous searches. Defaults to false |
| binddn | String | The bind DN to use for ldap searches. Only used when anonymous is set to false. Defaults to "" |
| bindpwd | String | The bind password to use for ldap searches. Only used when anonymous is set to false. Defaults to "" |
| userAttribute | String | The LDAP schema attribute used to identify the user name. Defaults to uid |
| userNumberAttribute | String | The LDAP schema attribute used to identify the user id number. Defaults to uidNumber |
| groupAttribute | String | An LDAP schema attribute to use for retrieving group information. This is a required configuration |
| groupNameAttribute | String | An LDAP schema attribute to use for identifying the group set in groupAttribute. Defaults to cn |
| cacheSpecification | String | The guava cache specification to use for LDAP, as described in com.google.common.cache.CacheBuilderSpec. Defaults to "expireAfterWrite=30s". |
authentication {
type = ldap
ldap {
host = "localhost"
groupAttribute = "uniqueMember"
searchbase = "dc=example,dc=org"
usersub = "ou=people"
groupsub = "ou=groups"
cacheSpecification = "expireAfterWrite=30s"
}
}
File Authentication Namespace authentication.file
The file format used is a variation on that used by Apache. You can find a sample script for generating
users and passwords in scripts/gen_passwords.sh.
| Key | Type | Description |
|---|---|---|
| userfile | String | The file to look in for auth information |
| cacheSpecification | String | The guava cache specification to use for file-based auth, as described in com.google.common.cache.CacheBuilderSpec. Defaults to "expireAfterWrite=30s". |
authentication {
type = file
file {
userfile = "conf/users.conf"
cacheSpecification = "expireAfterWrite=30s"
}
}
Mixed Authentication
Mixed authentication allows collins to use multiple authentication backends simultaneously. An example use-case could be a scenario where real users live in LDAP but system users (for automation etc.) are defined using file authentication.
To use mixed authentication, simply specify a list of authentication backends as the type, and add configuration (as described above) for each of them within the authentication block. A simple example can be seen below.
The mixed authentication provider will try each of the methods in the order listed and use the first one that returns a successful match.
authentication {
type = "file,ldap"
file {
userfile = "conf/users.conf"
}
ldap {
host = "localhost"
groupAttribute = "uniqueMember"
searchbase = "dc=example,dc=org"
usersub = "ou=people"
groupsub = "ou=groups"
}
}
Cache
Caching used by collins
Collins uses caching in several places, most notably to cache ldap responses, metrics, and to coordinate across multiple nodes for the firehose.
| Key | Type | Description |
|---|---|---|
| enabled | Boolean | Whether to enable the cache. Defaults to true |
| type | String | The type of cache to use. Valid options are in-memory for guava based cache or distributed for hazelcast based cache. in-memory is only valid for a standalone collins setup - if you have multiple collins servers, you should switch to using the distributed cache. Defaults to in-memory |
cache {
enabled=true
type=in-memory
}
Guava in-memory cache
Guava cache is only suitable for standalone setup. It is used to cache various information internally to collins.| Key | Type | Description |
|---|---|---|
| enabled | Boolean | Whether to enable guava cache. Defaults to true. If you choose in-memory for your cache type, you must set this configuration to true as well. |
| specification | String | The global guava cache specification, as decribed in com.google.common.cache.CacheBuilderSpec. Defaults to "maximumSize=10000,expireAfterWrite=10s,recordStats" |
guava {
enabled=true
# used when deploying in standalone mode
specification="maximumSize=10000,expireAfterWrite=10s,recordStats"
}
Hazelcast distributed cache
Hazelcast is used for multi-node distributed cache. It was introduced to support the firehose feature.| Key | Type | Description |
|---|---|---|
| enabled | Boolean | Whether to enable the hazelcast. Defaults to true. If you choose distributed for your cache type, you must set this configuration to true as well. |
| configFile | String | Path to the XML config file used by hazelcast. See http://docs.hazelcast.org/docs/3.5/manual/html/tcp.html for details. See https://github.com/tumblr/collins/blob/master/conf/hazelcast/hazelcast.xml for a working example. |
| members | String | List of IP addresses of existing hazelcast members. Make sure this includes at least one other collins IP, so the collins nodes can find each other. |
hazelcast {
enabled=false
# http://docs.hazelcast.org/docs/3.5/manual/html/tcp.html
# used when deploying in clustered mode
configFile="conf/hazelcast/hazelcast.xml"
members=""
}
}
Callbacks
Hooking into lifecycle events in collins
Namespace callbacks
Collins supports a callback mechanism that allows you to trigger events when the configured callbacks are matched. A short example is probably most useful here.
callbacks.registry {
hardwareProblem {
on = "asset_update"
when {
previous.state = "!isMaintenance"
current.state = "isMaintenance"
current.states = [ HARDWARE_PROBLEM ]
}
action {
type = exec
command = "/sbin/notify <tag> sysadmin@example.org"
}
}
}
In the above configuration we have registered a callback named hardwareProblem. This callback will be triggered when an asset is moved to have a status of Maintenance with a state of HARDWARE_PROBLEM. When the callback is triggered we will execute a notify command that will email a systems administrator.
A callback is triggered by an event which is specified via the on config value. The value is
then matched using a matcher which is specified via the when config value. If the matcher
succeeds the specified action is taken.
| Key | Type | Description |
|---|---|---|
| enabled | Boolean | Defaults to true. Do not disable as some cache maintenance is done via callbacks. |
| class | String | The callback implementation to use. Defaults to collins.callbacks.CallbackManagerPlugin |
| registry | Object | A set of named objects describing various callback scenarios |
callbacks {
enabled = true
class = "collins.callbacks.CallbackManagerPlugin"
registry {
}
}
Registry Namespace callbacks.registry
The registry holds all your configured callbacks.
| Key | Type | Description |
|---|---|---|
| on | String | The condition to match on. Required. Valid values are below.
|
| when | Object | Has previous state/states and current state/states as keys. These describe how to match whether the action should be triggered or not. |
| action | Object | Valid keys in the action are type (exec, collinscript) and a command |
Features
Collins feature flags
Namespace features
There are a number of parts of collins that you may wish to customize based on your environment. These are referred to in the reference configuration and elsewhere as feature flags. Available feature flags are documented below.
| Key | Type | Description |
|---|---|---|
| allowTagUpdates | String | A set of managed tags that can be updated for non-server assets |
| allowedServerUpdateStatuses | Set[String] | A set of statuses in which collins will accept LLDP/LSHW/CHASSIS_TAG updates for server assets. Maintenance is always a member of this set, even if not specified. |
| defaultLogType | String | Used for logs being created via the API when no type is specified |
| deleteIpmiOnDecommission | Boolean | Whether IPMI info should be deleted when an asset is decommissioned |
| deleteIpAddressOnDecommission | Boolean | Whether IP address information should be deleted on decommission |
| deleteMetaOnDecommission | Boolean | Whether attributes should be deleted on decommission |
| deleteSomeMetaOnRepurpose | Set[String] | If deleteMetaOnDecommission is false, this is a list of attributes to delete anyhow |
| encryptedTags | Set[String] | A list of attributes that should be encrypted. The ability to read and write these tags is controlled by the feature.canSeeEncryptedTags permission and the feature.canWriteEncryptedTags permission, respectively. |
| hideMeta | Set[String] | A list of tags to hide from display |
| ignoreDangerousCommands | Set[String] | A list of tags of assets that should ignore dangerous commands. You should populate this with tags of hosts that shouldn't be allowed to be powered off, reprovisioned, etc. |
| intakeSupported | Boolean | Whether the web based intake is supported or not |
| intakeIpmiOptional | Boolean | Whether the intake process may skip UID verification for assets without IPMI configuration. |
| keepSomeMetaOnRepurpose | Set[String] | If useWhitelistOnRepurpose is true, this is a list of attributes to keep |
| noLogAssets | Set[String] | A set of assets not to log any changes for |
| noLogPurges | Set[String] | A set of tags not to log when they change |
| searchResultColumns | Set[String] | A set of attributes to display on search results page. Defaults to [TAG, HOSTNAME, PRIMARY_ROLE, STATUS, CREATED, UPDATED] |
| sloppyStatus | Boolean | Should be true if you want collins to be usable. |
| sloppyTags | Boolean | Should probably be false. Allow every tag to be updated/overwritten/changed no matter what. Normally managed tags can only be updated during certain parts of the asset lifecycle. |
| useWhitelistOnRepurpose | Boolean | Determines which of deleteSomeMetaOnRepurpose or keepSomeMetaOnRepurpose is used. When true keepSomeMetaOnRepurpose is used. |
features {
allowTagUpdates = []
allowedServerUpdateStatuses = []
defaultLogType = Informational
deleteIpmiOnDecommission = true
deleteIpAddressOnDecommission = true
deleteMetaOnDecommission = false
deleteSomeMetaOnRepurpose = []
encryptedTags = []
ignoreDangerousCommands = []
intakeSupported = true
hideMeta = []
noLogAssets = []
noLogPurges = []
sloppyStatus = true
sloppyTags = false
}
features {
allowedServerUpdateStatuses = [ PROVISIONED, PROVISIONING ]
encryptedTags = [SYSTEM_PASSWORD, LOCATION]
noLogAssets = [chatty_config, other_chatty_config]
noLogPurges = [SYSTEM_PASSWORD]
}
Views
Generic framing support for external tools
Overview Namespace views
In order to generically support external utilities to provide supplemental data for assets, a generic view system was implemented to allow operators to frame in arbitrary sites. This supplants the graphs plugin, and is used to provide easy access to tooling like Grafana, Nagios/Icinga, Prometheus, etc.
| Key | Type | Description |
|---|---|---|
| frames | Map[String]Frame | A map of frames to conditionally evaluate on any given asset. See examples. |
| enabled | Boolean | Defaults to false |
Frames Namespace views.frames
| Key | Type | Description |
|---|---|---|
| enabled | Boolean | Enable this frame or not (default false) |
| title | String | Title to display on asset tab bar |
| style | String | HTML style tag to apply to the iframe. A good default is width: 100%;height: 1200px; |
| script | String | JS script to inject into the view to determine what the URL is to frame in, and how to decide if the tab should be marked as active or not. You can specify function isEnabled(jsonObj) and function getUrl(jsonObj). See examples. |
views {
enabled = true
frames = {
# frame in grafana
graph {
enabled = true
title = "Grafana"
style = "width: 100%;height: 1200px;"
script = """
// if the asset is a server, and has a hostname, enable this tab
function isEnabled(inp) {
var obj = JSON.parse(inp);
return ((obj.ASSET.TYPE === "SERVER_NODE" || obj.ASSET.TYPE === "SWITCH") && ("HOSTNAME" in obj.ATTRIBS[0]));
}
// all assets use the host-stats dashboard
function getUrl(inp) {
var obj = JSON.parse(inp);
var dash = "host-stats"
if (obj.ASSET.TYPE === "SWITCH") {
dash = "switch-stats";
}
return "https://grafana.company.net/dashboard/db/" + dash + "?var-hostname=" + obj.ATTRIBS[0]["HOSTNAME"];
}
"""
}
# frame in nagios
monitoring {
enabled = true
title = "Nagios"
style = "width: 100%;height: 1200px;"
script = """
function isEnabled(inp) {
var obj = JSON.parse(inp);
return ((obj.ASSET.STATUS === "SERVER_NODE") && ("HOSTNAME" in obj.ATTRIBS[0]));
}
function getUrl(inp) {
var obj = JSON.parse(inp);
return "https://nagios.company.net/nagiosxi/includes/components/xicore/status.php?show=hostdetail&host=" + obj.ATTRIBS[0]["HOSTNAME"];
}
"""
}
}
}
The above example configures 2 tabs. One frames in Grafana, showing a different dashboard depending on if the asset is a Server or Switch. The other frames in Nagios for the Server asset. This can be trivially extended to support PagerDuty, Prometheus, Alertmanager, Sensu, and any other monitoring, graphing, or alerting system. All that is required is the ability to parameterize the URL to the system with some identifying attribute of the host (hostname, IP, asset tag, etc).
Graphs
Display trending data
WARNING The graph namespace has been deprecated in favor of the more flexible and generic views namespace
Overview Namespace graph
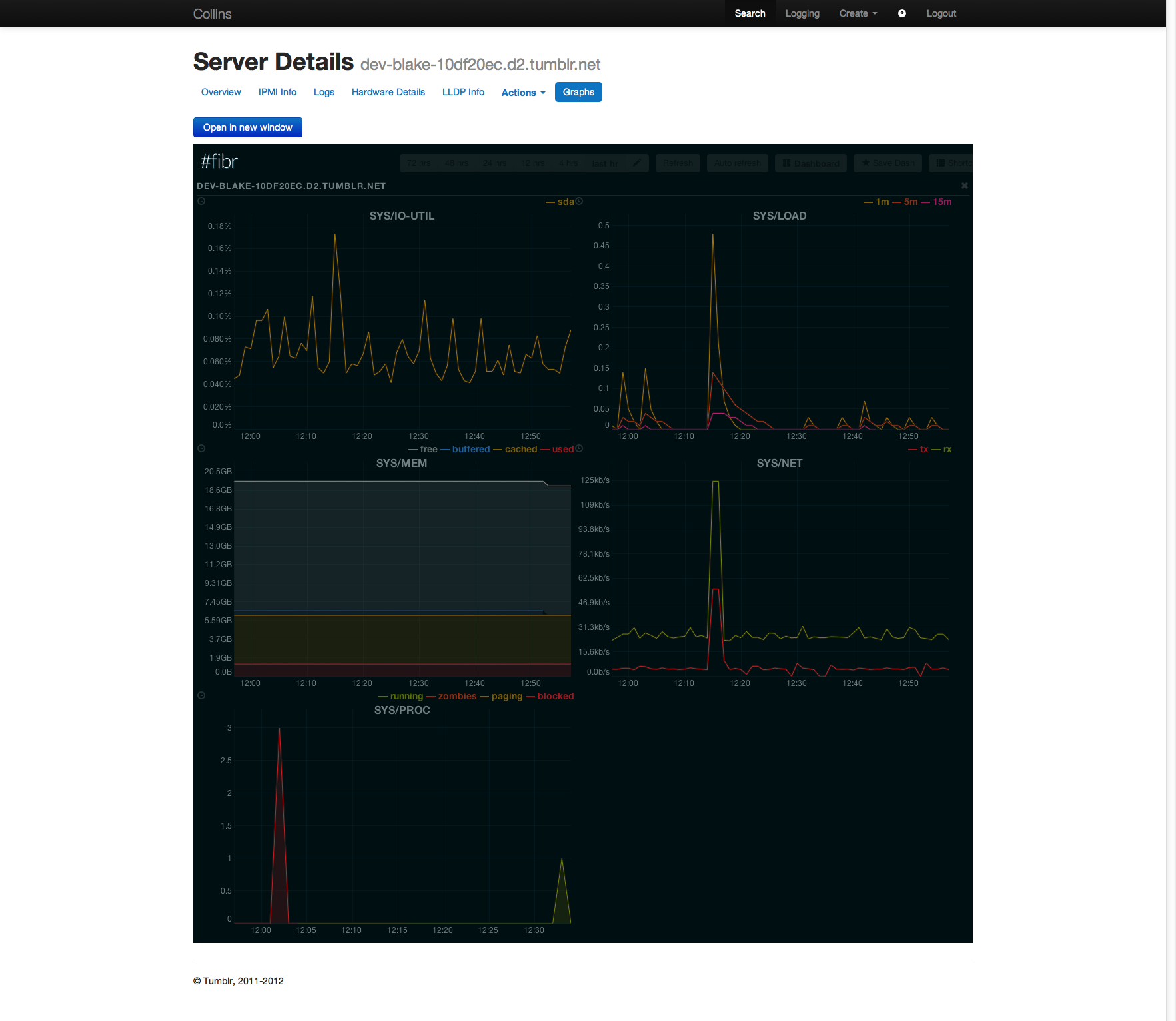
Collins has an easy to implement plugin for graph and trending systems, which can be extended to support any framed in HTML content. The graph plugin will display embedded graphs or charts for assets, or just links to those systems (depending on the graph plugin). Once enabled, you will find an additional tab on the asset details screen named 'Graphs' with all the configured information available in it.
There is currently support for Fibr, the OpenTSDB visualization tool we built at Tumblr (currently closed source!), and ganglia. There are no plans to opensource Fibr at this time.
| Key | Type | Description |
|---|---|---|
| class | String | Class that implements the neccesary graph plugin. Defaults to collins.graphs.FibrGraphs |
| enabled | Boolean | Defaults to false. |
| cacheSpecification | String | The guava cache specification to use for metrics cache, as described in com.google.common.cache.CacheBuilderSpec. Defaults to "maximumSize=2000,expireAfterWrite=60s". |
Fibr Graphs Namespace graph.FibrGraphs
At Tumblr, Fibr is our primary trending, graphing, and systems visualization tool. NOTE: this has been deprecated in favor of the more generalized framing system.
| Key | Type | Description |
|---|---|---|
| annotations | Set[String] | Annotations to display with graphs. Defaults to [deploy] (show deploy lines) |
| customMetrics | Object | Metrics to display based on asset information |
| defaultMetrics | Set[String] | Metrics to display for any asset. Defaults to SYS/LOAD, SYS/MEM, SYS/NET, SYS/PROC, SYS/IO-UTIL |
| timeframe | Duration | What timeframe to display for the metrics. Defaults to 1 hour (shows 1 hour of data). |
| url | URL |
The Fibr web URL. Defaults to http://fibr.d2.tumblr.net/ which is almost certainly
not suitable outside of Tumblr.
|
graph.FibrGraphs {
customMetrics = {
mysqlHosts {
selector = "PRIMARY_ROLE = \"DATABASE\""
metrics = [
MYSQL/COMMANDS,
MYSQL/SLOW,
MYSQL/THREADS,
MYSQL/NET
]
}
memcacheHosts {
selector = "POOL = MEMCACHE*"
metrics = [
MEMCACHE/COMMANDS,
MEMCACHE/EVICTS,
MEMCACHE/ITEMS,
MEMCACHE/HITRATIO
]
}
}
}
In the above example, hosts that have a PRIMARY_ROLE of DATABASE will
display in addition to the default metrics, the MySQL specific metrics. Assets with a POOL
matching MEMCACHE* will additionally display memcache specific metrics.
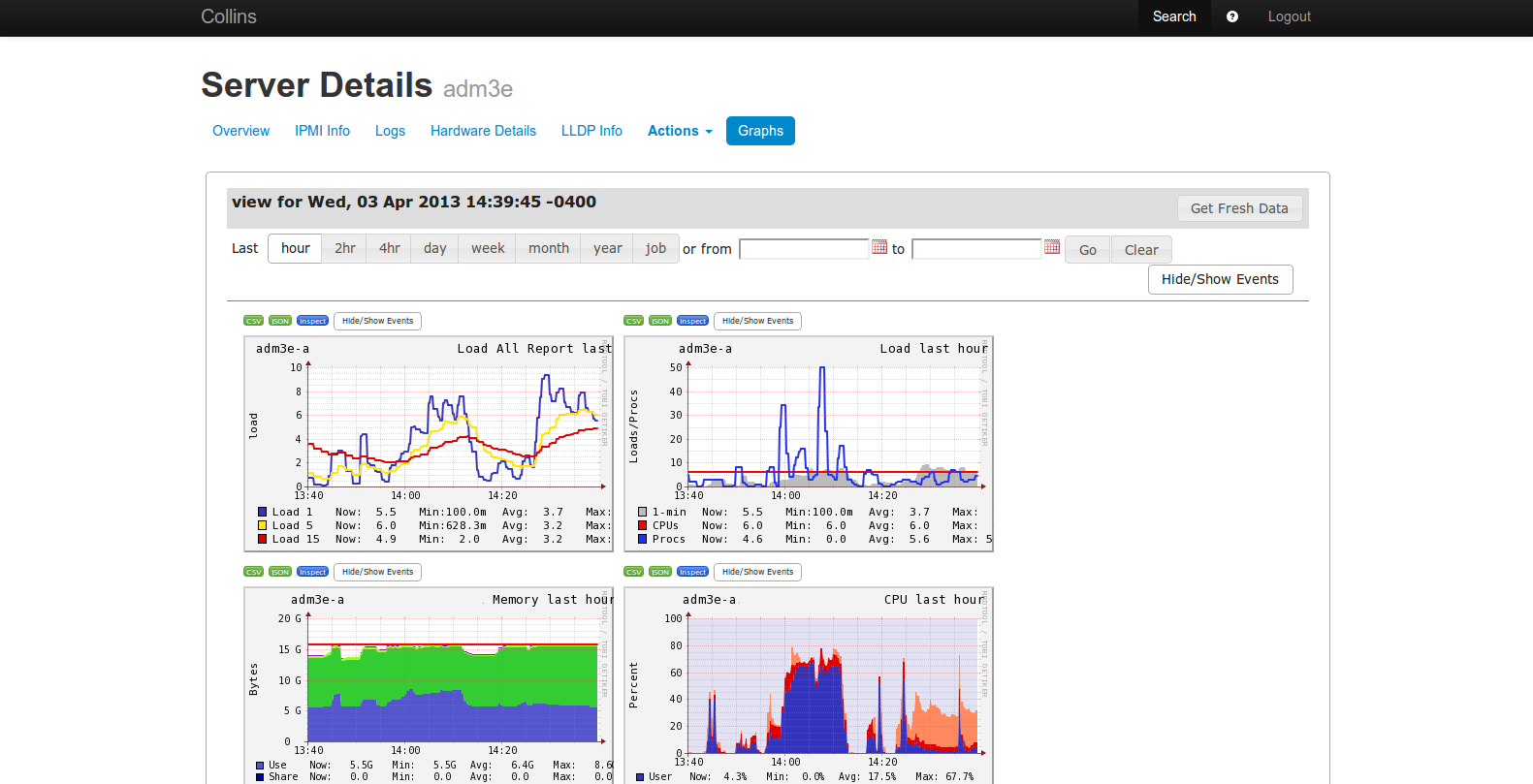
Ganglia Graphs Namespace graph.GangliaGraphs
Ganglia is a distributed metrics generation, collection, and visualization system. Collins integration relies on recent ad-hoc-views support.
| Key | Type | Description |
|---|---|---|
| url | String | Location of the ganglia web ui. |
| timeRange | String | Default time range to display in the UI. Defaults
to 1hr. Options available will depend on your
ganglia setup. |
| hostSuffix | String | By default ganglia uses reverse dns to determine hostnames.
That means a server with a hosname of foo might
show up as foo.example.com. If your reverse dns
scheme has a consistent suffix, you can supply it here. |
| defaultGraphs | Set[String] | gweb veiws makes a distinction between "graphs" (or reports)
and individual metrics. "graphs" are pre-defined and can
combine multiple metrics whiel metrics just display a single
value. Defaults to "load_all_report", "load_report",
"mem_report", "cpu_report", "network_report",
"packet_report". |
| defaultMetrics | Set[String] |
Which individual metrics to display. Defaults to "disk_free", "disk_total".
|
graph {
class = "collins.graphs.GangliaGraphs"
enabled = true
GangliaGraphs {
url = "http://my-ganglia.domain.local/"
}
}
Ip address
IPAM Configuration
Namespace ipAddresses
The Collins IPAM configuration is pretty straight forward. You specify more or less a set of pools that are available for allocation. Once configured, assets can have addresses from any of these pools assigned to them.
| Key | Type | Description |
|---|---|---|
| defaultPoolName | String | If no pool name is specified, this is the one to use. Defaults to DEFAULT. |
| strict | Boolean | If true (default), refuse to create addresses in undefined pools. This is primarily useful to set to false if you don't control your IP space and you get addresses from a 3rd party. |
| pools | Object | A configured set of pools to allocate from |
ipAddresses {
pools {
DEV {
startAddress = "172.16.4.4"
network = "172.16.4.0/28"
}
ROW_1_1 {
name = "ROW_1.1"
startAddress = "172.16.64.5"
network = "172.16.64.0/24"
}
}
}
The above configuration now allows you to allocate addresses out of two pools, a DEV pool and a ROW_1.1 pool. Notice that the ROW_1.1 pool had to specify a name. This is because an object name can not contain a period so must actually set the name manually as a string. The DEV pool did not have to do this. At Tumblr we have found pool names most useful for mapping to a particular VLAN and handling VLAN assignments using this information.
Pool Config
Each pool can take a name, gateway, startAddress and network.
| Key | Type | Description |
|---|---|---|
| name | String | The name of the pool. Defaults to the key of the pool. |
| network | String | The network to use for address allocation in CIDR notation. Defaults to 10.0.0.0/16. |
| startAddress | Option[String] | The IP address to use to start allocating addresses at. Defaults to 10.0.0.10. |
| gateway | Option[String] | If the gateway is not in the network range, specify it here |
Gpus
Collecting GPU information
Namespace gpu
GPU information can be stored in collins by adding GPU vendors to a whitelist. By default, any NVIDIA GPUs (PCI vendor = "NVIDIA Corporation") will be parsed from lshw XML data and added to collins.
Additional vendors can be added by updating the configuration with their PCI vendor information.
| Key | Type | Description |
|---|---|---|
| supportedVendorStrings | Set[String] | PCI vendor strings to whitelist when parsing LSHW output. Defaults to ["NVIDIA Corporation"]. |
gpu {
supportedVendorStrings = ["NVIDIA Corporation", "Advanced Micro Devices, Inc. [AMD/ATI]"]
}
Ipmi
Configuring your IPMI network and authentication setup
Namespace ipmi
The IPMI configuration is used to drive generation of IPMI addresses, usernames and passwords. This information is used for power management operations such as power cycling an asset or lighting up an asset during the intake process.
| Key | Type | Description |
|---|---|---|
| passwordLength | Integer | The length of the generated password. Defaults to 12. |
| randomUsername | Boolean | If false, uses the configured username. If true, generates a username based on the asset tag. Defaults to false. |
| username | String | Used when randomUsername is false. Defaults to root. |
| network | String | The network to use for address allocation in CIDR notation. Defaults to 10.0.0.0/16. |
| startAddress | Option[String] | The IP address to use to start allocating addresses at. Defaults to 10.0.0.10. |
| gateway | Option[String] | If the gateway is not in the network range, specify it here |
ipmi {
passwordLength = 12
randomUsername = false
username = "root"
network = "10.0.0.0/16"
startAddress = "10.0.0.3"
}
Lldp
Configuration for importing LLDP data
Namespace lldp
Collins accepts XML output from lldpctl in order to store data about which switch an asset is connected to.
| Key | Type | Description |
|---|---|---|
| requireVlanName | Boolean | If true, throw an error if the LLDP data submitted contains any VLANs without a name attribute. Defaults to true. |
| requireVlanId | Boolean | If true, throw an error if the LLDP data submitted does not contain a
VLAN with a vlan-id attribute. Defaults to false. |
lldp {
requireVlanName = true
requireVlanId = false
}
Monitoring
Monitoring Collins
Namespace metricsreporter
Monitoring Collins using Coda Hale's Metrics and Chris Burrough's metrics-reporter-config project is relatively straightforward. See Metrics' documentation for how to report specific metrics, and the metrics-reporter-config documentation for how the configuration file should be formatted.
| Key | Type | Description |
|---|---|---|
| enabled | Boolean | true to enable, false to disable. false by default.
|
| configFile | String | The cofig file passed to metrics-reporter-config |
metricsreporter {
enabled= false
configFile = "conf/metrics-reporter-config.yaml"
}
Multicollins
For when a single data center just isn't enough
Namespace multicollins
When Tumblr grew into a second datacenter, we didn't want to bother with having to setup multi-master replication across sites or do some kind of master site replication scheme. Instead what we decided is that we would make each Collins instance aware of each other, and allow them to query and interact with each other. Don't worry, no crazy zookeeper magic going on here.
If you have multiple independent collins installations setup, to make them aware of each other you have to do two things.
- Configure multi-collins
- Create an appropriate asset in each collins instance
| Key | Type | Description |
|---|---|---|
| enabled | Boolean | True to enable, false to disable. False by default. |
| instanceAssetType | String | Name of the asset type that represents a remote datacenter. Defaults to DATA_CENTER |
| locationAttribute | String | The tag on the instanceAssetType that provides collins with authentication information for the remote collins instance. This should be in URL format including credentials, e.g. http://username:password@remoteHost:remotePort. Don't worry, you can control who can see this with the features.canSeeEncryptedTags permission. |
| thisInstance | String | The asset tag that is for this specific instanceAssetType. For instance if the collins instance you are configuring is in EWR01, and the remote instance is in JFK01, you should set thisInstance to EWR01. |
| queryCacheTimeout | Integer | The amount of time (in seconds) to cache the query responses from remote collins instances. A value of 0 will result in values never expiring from the cache, which you probably do not want. Defaults to 30 seconds. |
| cacheEnabled | Boolean | Optionally enable or disable the multicollins cache. True, meaning enabled, by default. |
multicollins {
enabled = false
instanceAssetType = DATA_CENTER
locationAttribute = LOCATION
thisInstance = NONE
queryCacheTimeout = 30
cacheEnabled = true
}
Once you have configured multicollins you will now be able to use the remoteLookup API parameter for
asset finds. The Ruby client automatically handles fetching remote assets when needed. Additionally, you should find a 'Remote Search' checkbox in the search UI.
Node classifier
Find similar assets
Namespace nodeclassifier
A pretty common thing to want to be able to do is ask collins to tell you what other assets are like another. At Tumblr we use this for bulk provisioning, where I might want to be able to do something like say 'provisioning me 100 servers that are just like this one'. This is the problem that is solved with the node classifier. A node classifier describes a node class (e.g. web, queue, database, etc) and allows you to query for assets described by the classifier.
Much like with the MultiCollins configuration, we reuse assets to configure our node classifiers.
In order to create a node classifier create a new asset (we prefer Configuration assets), and set
tags on it that describe the traits of similar assets. For instance you might create a Configuration
asset named web_classifier and set the NIC_SPEED to 10000000000, the MEMORY_SIZE_TOTAL to
34359738368, and the TOTAL_DISK_STORAGE to 500107862016. This configuration now describes a web class host with
a 1Gb NIC, 32GB of RAM, and a 500GB disk. Be sure to set an IS_NODECLASS tag to true on the asset.
With the above configuration specified you can now use the find similar API endpoint. You also in the web UI should find links for finding similar assets.
| Key | Type | Description |
|---|---|---|
| assetType | String | The asset type for classifiers. Defaults to CONFIGURATION. |
| identifyingMetaTag | String | The tag that indicates that the asset is indeed a classifier. Defaults to IS_NODECLASS. |
| excludeMetaTags | Set[String] | A set of tags to exclude from finding similar assets. IS_NODECLASS and NOTE are included by default. |
| displayNameAttribute | String | What attribute to use for a friendly name for this classification, instead of the tag of the classification asset. Defaults to NAME. |
| sortKeys | Set[String] | Tags to be used for sorting. This is useful for instance for specifying that ROW, followed by RACK should be used for location based ordering of results. We use this at Tumblr to provide good distribution when provisioning. |
nodeclassifier {
assetType = CONFIGURATION
identifyingMetaTag = IS_NODECLASS
displayNameAttribute = NAME
excludeMetaTags = [IS_NODECLASS, NOTE]
sortKeys = []
}
Power configuration
Power requirements for assets
Namespace powerconfiguration
Overview
Depending on the environment, each asset may have a different power configuration. A power configuration specifies the number of power units required per asset, the number of power components required per power unit, and various requirements for each power component.
Definitions
- An asset may have an associated power configuration
- A power configuration consists of one or more power units
- A power unit consits of one or more power components (e.g. power strip, power outlet, etc)
- A set of power units represents a complete power configuration
You can think of an asset power configuration as looking something like the following.
-
PowerConfiguration
-
Power Unit 1
- Power Component 1
- Power Component 2
- Power Component n
- Power Unit 2
- Power Unit n
-
Power Unit 1
Configuration
| Key | Type | Description |
|---|---|---|
| unitComponents | Set[String] | A set of components in a power configuration. Defaults to [PORT, OUTLET] |
| uniqueComponents | Set[String] | Components that must be unique for a single asset. Defaults to [PORT] |
| unitsRequired | Integer | Number of power units required for intake. Defaults to 1. |
| useAlphabeticNames | Boolean | Whether power units should use alphabetic names or not, defaults to true. The default configuration will result in POWER_PORT_A, POWER_OUTLET_A. If unitsRequired were 2 it would also include POWER_PORT_B and POWER_OUTLET_B. If useAlphabeticNames is false, instead of A/B it would be 1/2. |
Note that this configuration heavily influences the intake process as well as what API parameters are available for asset updates. You can get a sample for what the asset looks like in the Asset Get JSON response.
Messages
It is possible to customize how the various components are labeled. The default bundled messages defines the following messages.
- powerconfiguration.unit.port.label - Power Strip {0}
- powerconfiguration.unit.outlet.label - Outlet {0}
Notice that the configured components each get a unit label. This allows you to customize how the intake screen looks.
Power managment
With great power, comes great responsibility
Namespace powermanagement
Assuming you would like the ability to perform power management operations on devices, such as power cycling them or powering them off, you will want to provide a power management configuration.
| Key | Type | Description |
|---|---|---|
| enabled | Boolean | Set to true to enable, defaults to false. |
| class | String | Defaults to "util.plugins.IpmiPowerManagement" which is probably suitable for your environment. |
| timeout | Duration | Defaults to 10 seconds. Do not increase as this will reduce concurrency on the system. |
| allowAssetTypes | Set[String] | Asset types that can be power managed. Defaults to [SERVER_NODE]. |
| allowAssetsWithoutIpmi | Boolean | Allow power actions on assets that do not have IPMI information. Defaults to false. |
| disallowStatus | Set[String] | Set of status types where power management should not be enabled. Defaults to empty set. |
| disallowWhenAllocated | Set[String] | Set of power actions to disable when an asset is allocated. Defaults to powerOff. |
| commands | Object | Defines the commands to execute when a power action is called. |
powermanagement {
enabled = true
command_template = "ipmitool -H <host> -U <username> -P <password> -I lan -L OPERATOR"
allowAssetTypes = [SERVER_NODE]
allowAssetsWithoutIpmi = false
disallowStatus = []
disallowWhenAllocated = [powerOff]
commands {
powerOff = ${powermanagement.command_template}" chassis power off"
powerOn = ${powermanagement.command_template}" chassis power on"
powerSoft = ${powermanagement.command_template}" chassis power soft"
powerState = ${powermanagement.command_template}" chassis power status"
rebootHard = ${powermanagement.command_template}" chassis power cycle"
rebootSoft = ${powermanagement.command_template}" chassis power reset"
identify = ${powermanagement.command_template}" chassis identify <interval>"
verify = "ping -c 3 <host>"
}
}
Note A command must be specified for every power action.
| Action | Description |
|---|---|
| powerOff | Power off. |
| powerOn | Power on. |
| powerSoft | ACPI power off. |
| powerState | Power status, should have 'on' in stdout if the device is on. |
| rebootHard | Power cycle |
| rebootSoft | ACPI reboot |
| identify | Turn on the IPMI light for <interval> seconds |
| verify | A command to run if the IPMI command fails. Should exit 0 if the host is reachable and exit 1 otherwise. |
| Substitution | Value |
|---|---|
| <tag> | The tag of the asset being operated on |
| <username> | The IPMI username associated with the asset |
| <password> | The IPMI password associated with the asset |
| <host> | The IPMI address associated with the asset |
| <interval> | The interval to keep the light on for. 60 seconds. |
Provisioning
Setup provisioning for your environment
Namespace provisioner
The provisioner plugin adds asset provisioning capabilities to collins which can be driven via the API or the web UI.
| Key | Type | Description |
|---|---|---|
| allowedStatus | Set[String] | Only machines that have a status listed here can be provisioned. Defaults to [Unallocated, Maintenance, Provisioning, Provisioned] |
| allowedType | Set[String] | Only assets with this type can be provisioned. Defaults to [SERVER_NODE, SERVER_CHASSIS] |
| enabled | Boolean | Defaults to false |
| cacheSpecification | String | The guava cache specification to use for the profiles file, as described in com.google.common.cache.CacheBuilderSpec. Defaults to "expireAfterWrite=30s". |
| checkCommand | String | A command that runs before the actual provison, should return 0 if provisioning can proceed or 1 otherwise. Defaults to /bin/true. |
| command | String | The command to run. Substitutions are of the form <foo> where foo is a supported substitution. Available substitutions are <tag>, <profile-id>, <notify>, <suffix> and <logfile>. Defaults to /bin/false |
| profiles | String | A YAML file containing all available provisioning profiles. |
| rate | String | How frequently users can provision hosts unless they are setup with the features.noRateLimit permission. Defaults to once every 10 seconds. |
| checkCommandTimeoutMs | Duration | Timeout for the execution of the checkCommand. Defaults to 40 seconds. |
| checkCommandTimeoutMs | Duration | Timeout for the execution of the command. Defaults to 40 seconds. |
provisioner {
allowedStatus = [Unallocated, Maintenance, Provisioning, Provisioned]
allowedType = [SERVER_NODE, SERVER_CHASSIS]
enabled = false
cacheSpecification = "expireAfterWrite=30s"
checkCommand = "/bin/true"
command = "/bin/false"
profiles = "test/resources/profiles.yaml"
rate = "1/10 seconds"
# How long to wait for provisioning commands, checkCommand / command
checkCommandtimeout = 40 seconds
commandtimeout = 40 seconds
}
Provisioning Rates
Rates are expressed in terms of the number of successful requests per time period that a user can
make. Specified as #/duration where # is an integer and duration
is the duration. Examples:
1/30 seconds- once per 30 seconds5/1 minute- five times per minute (same as1/20 seconds)1/0 seconds- no rate limit0/0 seconds- disallowed
Substitutions in Commands
A few substitutions are available in the command and checkCommand
<tag>- the asset tag being provisioned<profile-id>- the id of the profile being used for provisioning<notify>- the contact information supplied by the user doing the provisioning<suffix>- any suffix to append to the hostname as provided by the user (if allowed)<logfile>- a logfile to use, defaults to/tmp/<tag>-<profile-id>.log
Provisioner Profile
The provisioner profiles file is what tells collins what types of assets can be provisioned. It is a fairly simple format and leaves most actual work up to the command and check command configured CLI tools. At Tumblr we have implemented a variety of simple CLI tools to handle a variety of provisioning scenarios. Our infrastructure automation framework is called visioner, some sample visions will be distributed so you can see how some of our provisioning works.
The keys in the reference file below (databasenode, devnode, webnode) are
automatically set to be the NODECLASS tag of the asset in collins. This key is
also reference above as <profile-id> and is how the provision
process knows what configuration to use. A profile can have any number of
key/values associated with them of any type, but has a few reserved key/value
pairs.
profiles:
databasenode:
label: "Database Server"
prefix: "db"
primary_role: "DATABASE"
requires_pool: false
contact: dbteam@company.com
contact_notes: http://wiki.company.com/servers/databasenode
clear_attributes:
- TEST_DATABASE
- DONT_WANT_THIS_ATTRIBUTE_EITHER
devnode:
label: "Dev Machine"
prefix: "dev"
allow_suffix: true
primary_role: "DEVEL"
pool: "DEVEL"
attributes:
DEV_MODE: true
hadoopnode:
label: "Hadoop Server"
prefix: "hadoop"
allowed_classes:
- storage_class
- service_class
webnode:
label: "Web Server"
prefix: "web"
requires_secondary_role: true
| Key | Type | Description |
|---|---|---|
| label | String | Label to show in the UI. Should be unique. |
| prefix | String | The prefix to use in the hostname. This (semi-readable hostnames) helps with viewing error logs and such. |
| primary_role | Option[String] | The primary role to set on the asset in collins. The primary role drives automation and other tasks. If this value is set, the user can not select it. |
| secondary_role | Option[String] | The secondary role to set on the asset in collins. If this value is set, the end user can not select it. |
| pool | Option[String] | The pool to set on the asset in collins. If this value is set, the end user can not select it. |
| requires_primary_role | Boolean | Whether a primary role is required or not, defaults to true. If primary_role is not specified, the user must select one. If this is set to false, the user does not have to select one. |
| requires_secondary_role | Boolean | Whether a secondary role is required or not, defaults to false. If secondary_role is not specified and this value is true, the user must specify one. If this value is false, the user is not required to specify the value. |
| requires_pool | Boolean | Whether a pool is required or not, defaults to true. If pool is not specified and this value is true the user must specify one. |
| allow_suffix | Boolean | Whether a user may specify an additional suffix for the hostname, defaults to false. If this is set to true, and the user for instance specifies a value of "foo" and the prefix was set to "dev", the generated hostname will be something like "dev-foo". |
| contact | Option[String] | If specified, this value is set on the CONTACT attribute at provision time. Useful to map responsible parties to nodeclasses. If not specified, CONTACT is cleared on the asset. |
| contact_notes | Option[String] | Similar to contact, this field can be used to store some kind of information about the nodeclass, i.e. a link to a wiki page about the node profile, or services running on the machine. If not specified, this will be cleared at provision time. |
| attributes | Map[String,Object] | If specified, any key value pair here will be set as attributes on the asset at provision time. You can use any value types that YAML supports; the parsed representation will be turned into a string when setting the attribute. These attributes have a lower precedence than attributes set by collins, such as nodeclass and primary_role. |
| clear_attributes | List[String] | If specified, any attribute in this list will be cleared on provision. These attributes have a lower precedence than any attributes set in attributes, and wont clear any attributes set by collins itsself (nodeclass, primary_role, etc) |
| allowed_classes | Option[List[String]] | A list of asset classification tags that an asset must be classified as to allow provisioning. The list is ORed, so an asset matching any of the classifications will be provisionable. If omitted, there are no restrictions placed on what asset can be used to provision this profile (any classified/unclassified asset will provision). This is useful to restrict certain nodeclasses to certain hardware profiles, i.e. hadoopnode requires storage_class assets. See docs on asset classification for details on how this works. |
Softlayer
Working with SoftLayer
Namespace softlayer
Although Collins was initially developed as Tumblr built out its own datacenter, we found it an excellent replacement for the SoftLayer web interface. The SoftLayer plugin provides support for cancelling servers, activating servers from the spare pool, and decorating tags that are SoftLayer specific.
Note The Collins system assumes that asset tags
associated with SoftLayer assets are of the form sl-ID where ID is the SoftLayer
ID.
| Key | Type | Description |
|---|---|---|
| enabled | Boolean | Defaults to false |
| username | String | Your SoftLayer username |
| password | String | Your SoftLayer API password |
| allowedCancelStatus | Set[String] | Assets with any of these status can be cancelled. |
| cancelRequestTimeoutMs | Duration | Timeout for canceling of a softlayer server. Defaults to 10 seconds. |
| activationRequestTimeoutMs | Duration | Timeout for activation of a softlayer server. Defaults to 10 seconds. |
softlayer {
enabled = true
username = "jimbob123"
password = "lkajsdlkjaas09823lkajdslkajsd"
allowedCancelStatus = [Unallocated, Allocated, Maintenance]
cancelRequestTimeout = 10 seconds
activationRequestTimeout = 10 seconds
}
The above configuration would perform operations as user jimbob and allow you to cancel assets in the specified status.
Solr
Better search
Namespace solr
If the Solr plugin is enabled, Collins will use Solr to index assets. Since you can run Solr either embedded (bundled into Collins) or using an external instance, you should almost definitely keep this enabled.
Once the Solr plugin is enabled you will notice a few new features pop up in Collins. First, you can now query collins using the collins query language. This allows you to perform more advanced queries using ranges (how many assets have between 4 and 8 CPUs, give me assets with more than 2TB of usable storage) and much more sophisticated boolean operators. You can also sort results by any tag which is nice. You can find example queries in the collins query language section of the recipes guide.
More information about these configuration settings can be found on the official Solr documentation
| Key | Type | Description |
|---|---|---|
| embeddedSolrHome | String | Embedded only Must be a writable directory if useEmbeddedServer is true |
| enabled | Boolean | Defaults to true |
| externalUrl | String | External only If useEmbeddedServer is false, this must be a valid solr URL |
| reactToUpdates | Boolean | Keep index up to date as assets and values are modified. Defaults to true. |
| repopulateOnStartup | Boolean | Defaults to false. Useful in dev. |
| useEmbeddedServer | Boolean | Defaults to true |
| socketTimeout | Int | External only Solr socket timeout for HTTP client. Defaults to 1000ms. |
| connectionTimeout | Int | External only Solr HTTP connection timeout. Defaults to 5000ms. |
| maxTotalConnections | Int | External only Solr HTTP client tunable; defaults to 100. |
| defaultMaxConnectionsPerHost | Int | External only Solr HTTP client tunable; defaults to 100. |
| assetBatchUpdateWindowMs | Int | Window in ms that the Solr Updater will attempt to batch asset updates in. Defaults to 10ms. Increasing this can reduce load on Solr if intaking an asset is triggering multiple asset update tasks. |
Tag decorators
Taking sexy back
Namespace tagdecorators
Tag decorators allow you to change how tags are displayed on asset. Creating links, formatting names, anything is fair game. The best way to illustrate is through an example.
tagdecorators {
templates {
search = "<a href=\"/resources?{name}={value}\">{value}</a>"
}
decorators {
APPLICATION_SHA.decorator = "<a target=\"_blank\" href=\"https://scm.site.net/commit/{value}\">{value}</a>"
CONTACT.decorator = "<a href=\"https://yourcompany.slack.com/messages/{value}\">{value}</a>"
CONTACT_NOTES.decorator = "<a target=\"_blank\" href=\"{value}\">{value}</a>"
RACK_POSITION {
decorator = ${tagdecorators.templates.search}
valueParser = "util.views.DelimiterParser"
delimiter = "-"
between = "-"
}
NODECLASS.decorator = ${tagdecorators.templates.search}
POOL.decorator = ${tagdecorators.templates.search}
PRIMARY_ROLE.decorator = ${tagdecorators.templates.search}
SECONDARY_ROLE.decorator = ${tagdecorators.templates.search}
BUILD_CONTACT.decorator = "<a href=\"https://yourcompany.slack.com/messages/{value}\">{value}</a>"
IP_ADDRESS {
decorator="<a href=\"ssh://{value}\">>{value}</a>"
between=", "
}
HYPERVISOR.decorator = "<a href=\"/resources?TAG={value}\">{value}</a>"
AVAILABILITY_ZONE.decorator = "<a href=\"/resources?IS_AVAILABILITY_ZONE=true&NAME={value}\">{value}</a>"
}
}
Thread pools
Thread Pool
Namespace akka
Configuring Collins akka pools is relatively straightforward. See the akka documentation for details. Collins makes use of a single akka dispatcher which can be configured in akka.actor.default-dispatcher. The dispatcher is shared for background processes and solr updates
Note Currently only on the development branch, scheduled for future release.
| Key | Description |
|---|---|
| background-processor | Configure for background processes, for instance ipmi invocations |
| solr_asset_updater | Configure for solr updates on asset modification |
| solr_asset_log_updater | Configure for updates on asset log modification |
akka {
actor {
default-dispatcher = {
fork-join-executor {
parallelism-factor = 1.0
}
}
deployment = {
/background-processor = {
dispatcher = default-dispatcher
router = round-robin
nr-of-instances = 128
}
/solr_asset_updater = {
dispatcher = default-dispatcher
}
/solr_asset_log_updater = {
dispatcher = default-dispatcher
}
}
}
}